Robust Frank-Wolfe Algorithm for Minimum Enclosing Bregman Balls
This post gathers theoretical convergence & complexity results on the Frank-Wolfe algorithm extended to Bregman divergences (instead of euclidian distance) and made robust to outliers. It is the result of a collaboration with Amaury Sabran, supervised by Pr Frank Nielsen (LIX).
We propose a robust algorithm to approximate the slack minimum enclosing ball problem for a broad class of distance functions called Bregman Divergences.
The slack minimum enclosing ball problem is a convex relaxation of the minimum enclosing ball problem that allows outliers. Bregman divergences include not only the traditional (squared) Euclidean distance but also various divergence measures based on entropic functions. We apply this algorithm to the case of Euclidean MEB, MEB in a Reproducing Kernel Hilbert Space and MEB on the probability simplex with KL-divergences.
Introduction
The minimum enclosing ball of a set of points is the smallest ball that contains all these points. Such balls are used in clustering [1] and classification [2] problems.
The Standard Minimum Enclosing Ball Problem
For the standard minimum enclosing ball problem, we consider an euclidean vector space and points in . The aim is to find the ball with minimum radius that contains all the points. This problem can be described as the following convex optimization problem :
The radius of the enclosing ball is .
The Slack-Bregman MEB Problem
We generalize this euclidian problem to the case where the distance is derived from a Bregman divergence. Bregman divergences include the standard Euclidean squared distance, the squared Mahalanobis distance and entropy-based distances such as the Kullback–Leibler divergence.
In addition, we generalize the hard-ball problem to slack-balls, i.e enclosing balls allowing outliers. To do so, we add slack variables in the optimization problem that penalize the presence of outliers. We control the amount of outliers with a slack parameter . For , we retrieve the hard enclosing ball problem.
The slack Bregman MEB problem (-SMEBB problem) is the following :
where is the canonical Bregman divergence defined in a following section.
Definition. A -Slack Minimum Enclosing Bregman Ball of , or -SMEBB of , is an optimal solution to this optimization problem.
Related work
The Frank-Wolfe algorithm
The first algorithm to iteratively solve a quadratic program on a simplex has been described by Frank and Wolfe in 1956 [3]. The algorithm computes the gradient of the function to minimize, and then makes a small step in the direction in which the gradient is the smallest. The convergence rate of this algorithm is , where is the number of steps. It means that the gap between the algorithm value and the optimal value at step is smaller than for some constant .
This algorithm could be directly applied to the Minimum Enclosing Ball problem. At each step of the algorithm, the gradient is smallest in the direction of the farthest point from the approximate ball center. This means that the center should make a small step toward the furthest point in the dataset. The objective function of this minization problem is not continuously differentiable; however, geometrical methods in [4] showed a similar convergence rate to the general Frank-Wolfe algorithm.
There exists many variants of the Frank-Wolfe algorithm, notably with the ideas of "line search" instead of fixed-size steps, away-steps, and partial computation of the gradient to speed up the algorithm. In this paper, we focused on the original definition of the Frank-Wolfe algorithm, but of course many variants could be adapted to the Bregman divergence-generalization.
Core-sets
Given a set of points , and , an -core-set is a subset of with the property that the smallest ball containing is within of the smallest ball containing . That is if the smallest ball that contains is expanded by , then the expanded ball contains .
Core-sets are related to the minimum enclosing ball problem because it is easier to compute an enclosing ball on a smaller subset of .
In [4:1], the algorithm to solve the minimum enclosing ball problem is to compute the center as a convex combination of the points in the dataset, and to iteratively add new points to the center representation. It has been shown that after iterations, the center is a convex combination of the points so that those points are an -core-set of . In [5], it is proven that the optimal size of an -core-set of any set of point is and that the bound is tight. This result is remarkable because it does not depend on the number of points in the dataset nor on the dimension of the data.
Therefore, theoretically, in the MEB problem, an -approximation of the MEB center could be expressed as a convex combination of at most points. When the dimension d is fixed and finite, the MEB center can always be expressed as a convex combination of at most points.
Our approach
Frank-Wolfe Algorithm for the Slack Bregman MEB problem
Main Result
Let be a vector space, a scalar product over and a non-negative integer.
Let a finite subset of .
Let be a convex, continuously differentiable function over .
For a function defined over a convex domain , we define the curvature constant :
Let be the Bregman divergence associated to and its canonical divergence as described in the following section.
We note :
and the canonical base of .
We define the Slack Bregman Frank-Wolfe algorithm, that output , the center and radius of the approximate -SMEBB.
-
Let
-
Let
-
For do:
-
-
-
-
Let be the indices of the largest entries of D (unsorted) with the index of the -th largest entry.
-
-
-
-
-
-
Let
-
Let
Theorem [Couairon, Sabran]. Let be a -SMEBB of . Let be the center and radius of the Bregman ball computed by the following algorithm during steps.
Then,
This algorithm lets us approximate the center of a Slack Bregman Minimum Enclosing ball with a convergence rate of .
Background Tools and results
In this post, we will not prove the above theorem, but we will present the tools we used from Bregman geometry and convex optimization.
Bregman Divergence
Let be a compact convex subset of . Let denote the Bregman divergence for a smooth strictly-convex real-valued generator .
.
Informally speaking, the Bregman divergence is the tail of the Taylor expansion. can be interpreted as the distance between and its linear approximation around as shown below. Since F is strictly convex, and iff .

Visualizing the Bregman divergence
Consider the dual convex conjugate of , . We have with . (and so that id). Define the canonical divergence .
We have
is convex in its first and second arguments.
We define a right-centered Bregman ball .
Given a finite set of points , the right-centered Minimum Enclosing Bregman Ball (rMEBB) is defined as the unique minimizer of
Wolfe Duality
Consider a general optimization problem:
The Lagrangian Dual problem is
Provided that the functions , , ... are convex and differentiable and that a solution exists, the infimum occurs when the gradient is equal to 0. The Wolfe Dual problem uses the KKT conditions as a constraint. The problem is therefore
Let us write the Wolfe dual to the SMEBB optimization problem.
By identification, we have
are convex and differentiable with respect to the variables , , . Therefore the Wolfe dual is
From now on, we define the following maps:
The Wolfe dual of the SMEBB problem can be simplified as
We define the Wolfe dual function over :
We can also write
this dual function is concave over .
Jaggi's theorem
The Slack Bregman Frank-Wolfe algorithm is the Frank-Wolfe optimization algorithm applied with the Wolfe dual problem of the SMEBB problem. The convergence theorem is from Jaggi (2008) [6].
Theorem [Jaggi, 2008]. Let be a convex, continuously differentiable function, and a compact convex subset of any vector space.;
Let and be the curvature constant of ;
Let be the duality gap:
Consider a sequence computed by the Frank-Wolfe algorithm :
- Let
- For do:
- Compute
- Update where
Then,
The duality gap is an upper bound of the difference between the values of the primal and dual functions.
Proof of the theorem
We only provide a sketch of the proof: First, we show that our algorithm is the Frank-Wolfe algorithm applied to where is the dual function of the -SMEBB problem. We then analyze to duality gap and show that .
Therefore,
Applications
The Frank-Wolfe algorithm lets us approximate the optimal solution to the SMEBB problem.
Definition. An slack Bregman MEB of a set of points is a couple such that if is an optimal solution to the slack Bregman Meb problem, then
With this definition, we have the following lemma:
Lemma. The number of iterations needed to compute a slack Bregman MEB of a set of points is .
Slack Minimum Enclosing Ball with the Euclidean Distance
In this section, are points in a vector space of finite dimension . We consider the euclidean scalar product on , which corresponds to the Bregman divergence associated to the generator .
The optimization problem is therefore the Minimum enclosing ball problem with outliers:
Theorem. The Slack Bregman Frank-Wolfe algorithm computes a -SMEBB of in time . where .
Proof. We first notice that for this Bregman divergence, .
With the previous lemma, we have shown that after iterations, the algorithm returns a -SMEBB of . Therefore one only need to show that each iteration can be computed in time .
With , we have and
For each iteration, we have computed in time , and . Therefore computing each of the coordinates of takes time .
Computing the -th largest entries of D takes time with the introselect algorithm and the remaining operations are all computed in time , hence the execution time of the algorithm is .
Our definition of a -SMEBB is not the same that the standard euclidian MEB approximation. Usually, a ball is an -approximation of the minimum enclosing ball if .A sufficient condition for to be an approximation of the MEB is . With this definition, the number of iteration needed is and therefore the total execution time is .
Kernelized Slack MEB
In real life, the data is not linearly separable, and euclidian enclosing balls do not reflect the geometry of a dataset. That is why it is interesting to map the data into a feature space through a kernel and to consider enclosing balls in this feature space.
In this section, are points in a vector space of finite dimension . We consider a mapping of into an unknown feature space such as
where k is a definite positive kernel, which means that
For instance, we could use the gaussian kernel:
.
We define . The representation of points in is implicit, which means that the center of the SMEBB is described as a convex combination of : .
Let be the Graham matrix of P, such that .
This scalar product corresponds to the Bregman divergence
associated to the generator
Theorem. The Slack Bregman Frank-Wolfe algorithm computes a -SMEBB of in time . where .
Proof. Since , the algorithm returns a -SMEBB of in . We only need to show that each iteration can be computed in time .
The only difficult point is to show that in the algorithm, is is possible to compute is time . We have
Since adding a constant term to does not change the computation of and , we can consider
The update rule of shows that the vector has at most non-empty entries. Therefore the computation of takes time , hence the total running time of .
Kullback-Leibler divergence
When working on a dataset that consist in points in the probability simplex, it is more natural to work with the Kullback-Leibler divergence than with the euclidian distance.
Let denote a point of the d-dimensional probability simplex.
For , let
and
The Kullback-Leibler divergence between two points P and Q of the d-dimensional probability simplex is
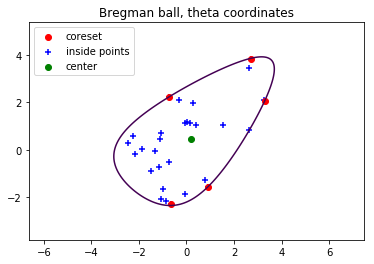
Hard Bregman ball

Bregman balls obtained with the FW Bregman MEB algorithm
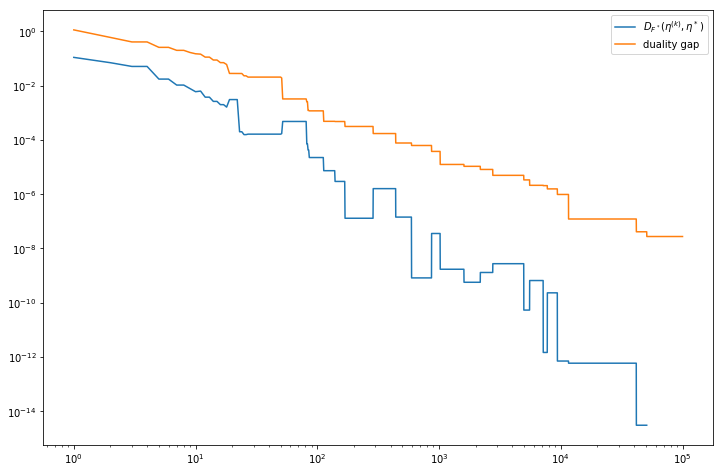
Center convergence rate and duality gap for FW Bregman MEB algorithm
Conclusion
We have considered the Frank-Wolfe algorithm for solving the Minimum Enclosing ball Problem and generalized it to Bregman divergences. We also considered an optimization problem with slack variables, which allow some outliers. We showed that the Frank-Wolfe algorithm can be run within this new framework, and demonstrated a convergence rate of where is the number of iterations, which is the same as what is proved in the Standard Euclidian MEB problem.
We showed three applications of this result: the standard euclidian slack MEB problem, the kernelized MEB problem where the enclosing ball is computed in a feature space, and MEB on the probability simplex with the Kullback-Leibler divergence.
Further studies may focus on the Nesterov Framework, which is a framework for non-smooth convex optimization. A convergence rate of is shown in [7].
The MEB problem with outliers on can be written as
with such as , and .
Therefore, one can apply the same method as in the paper for the Slack MEB problem, with instead of . The algorithm developped in this paper could also perhaps be generalized to Bregman divergences.
In another direction, when the approximated center is close enough to the real center, the variable in the algorithm stays roughly the same, so the computation of the largest entries of might be easier. It would be a good idea to study which structure should be maintained on the entries of so that the time complexity of this step decreases over time.
Appendix
Lemma. Let with , and .
The solution to the optimization problem is
where are the indices of the -th largest entries of , being the -th largest entry, and is computed in time .
Proof. Let be a partition of such that and
.
This partition can be computed in time , and is the set of indices of the -th largest entries of .
Let , , and .
and , therefore :
Therefore,
Ben-Hur, Asa and Horn, David and Siegelmann, Hava T and Vapnik, Vladimir, Support vector clustering, Journal of machine learning research, 2(Dec), 125-137, 2001 ↩︎
Tax, David MJ and Duin, Robert PW, Support vector data description, Machine Learning, 54(1):45-66, 2004 ↩︎
Frank, Marguerite and Wolfe, Philip, An algorithm for quadratic programming, Naval Res. Logist. Quart., 1956 ↩︎
Badoiu, Mihai and Clarkson, Kenneth L, Smaller core-sets for balls, In Proceedings of the fourteenth annual ACM-SIAM symposium on Discrete algorithms, pages 801-802, Society for Industrial and Applied Mathematics, 2003. ↩︎ ↩︎
Badoiu, Mihai and Clarkson, Kenneth L, Optimal core-sets for balls, Computational Geometry, 40(1): 14-22, 2008 ↩︎
Martin Jaggi, Revisiting Frank-Wolfe: Projection-Free Sparse Convex Optimization, Proceedings of the 30th International Conference on Machine Learning, volume 28 of Proceedings of Machine Learning Research, 2013, Available http://proceedings.mlr.press/v28/jaggi13.pdf. ↩︎
Ankan Saha and S. V. N. Vishwanathan, Efficient Approximation Algorithms for Minimum Enclosing Convex Shapes, CoRR, abs/0909.1062, 2009 ↩︎